
Generating Generators
This is a written version of a talk I presented at re:Clojure 2019. It’s not online yet but as soon as it is, I’ll include a link to the talk itself on YouTube.
Intro
The late phase pharma company has an interesting technical challenge. This is long past the stage of developing the drug. By this time, they’ve figured out that it is basically safe for humans to consume, and they’re executing on the last (and most expensive) part of the study. Testing it’s “efficacy”. That is whether it actually works. And sharing the supporting evidence in a way that the authorities can easily review and verify. And they just have this backlog of potential drugs that need to go through this process.
Bear in mind, I was the most junior of junior developers but from my perspective, what it seemed to boil down to (from an IT perspective) is that they have a succession of distinct information models to define, collect, analyze, and report on as quickly as possible.
As a consequence, they got together as an industry to define the metadata common to these information-models, so that they could standardize data transfer between partners. This was their “domain specific information schema”. CDISC. And it was great!
I worked for this really cool company called Formedix who understood better than most in the industry, the value of metadata (as opposed to data). And we’d help our clients use their metadata to
- Curate libraries of Study elements that could be re-used between studies
- Generate study definitions for a variety of “EDCs” who now had to compete with one another to win our clients’ business
- Drive data transformation processes (e.g. OLTP -> OLAP)
So my objective with this article is to introduce the metadata present in SQL’s information schema, and show how it can be used to solve the problem of testing a data integration pipeline. Hopefully this will leave you wondering about how you might be able to use it to solve your own organization’s problems.
The information schema
The information schema is a collection of entities in a SQL database that contain information about the database itself. The tables, columns, foreign keys, even triggers. Below is an ER diagram that represents the information schema. Originally created by Roland Bouman and now hosted by Jorge Oyhenard.

It is part of the SQL Standard (SQL-92 I believe), which means you can find these tables in all the usual suspects. Oracle, MySQL, PostgreSQL. But even in more “exotic” databases like Presto and MemSQL. The example I’ll be demonstrating later on uses MySQL because that was the system we were working with at the time but you should be able to use these techniques on any database purporting to support the SQL Standard.
The other point to note is that it presents itself as regular tables that you can query using SQL. This means you can filter them, join them, group them, aggregate them just like you’re used to with your “business” tables.
There is a wealth of information available in the information schema
but in order to generate a model capable of generating test-data to
excercise a data pipeline, we’re going to focus on two of the tables
in particular. The columns table, and the key_column_usage table.
Column/Type Information
As you might expect, in the columns table, each row represents a table
column and contains
- The column name
- The table/schema the column belongs to
- The column datatype
- Whether it is nullable
- Depending on the datatype, additional detail about the type (like the numeric or date precision, character length
Relationship Information
The other table we’re interested in is key_column_usage table. Provided
that the tables have been created with foreign key constraints, the
key_column_usage table tells us the relationships between the tables in
the database. Each row in this table represents a foreign key and contains
- The column name
- The table/schema the column belongs to
- The “referenced” table/schema the column points to
As an aside, it’s worth pointing out that this idea of “information-schemas” is not unique to SQL. Similar abstractions have sprung up on other platforms. For example, if you’re within the confluent sphere of influence, you probably use their schema registry (IBM have one too). If you use GraphQL, you use information-schemas to represent the possible queries and their results And OpenAPI (formerly known as Swagger) provides an information-schema of sorts for your REST API
Depending on the platform, there can be more or less work involved in keeping these information-schemas up-to-date but assuming they are an accurate representation of the system, they can act as the data input to the kind of “generator generators” I’ll be describing next.
Programming with Metadata
Lets say we’re building a twitter. You want to test how “likes” work. But in order to insert a “like”, you need a “tweet”, and a “user” to attribute the like to. And in order to add the tweet, you need another user who authored it. This is a relatively simple use-case. Imagine having to simulate a late repayment on a multi-party loan after the last one was reversed. It seems like it would be helpful to be able to start from a graph with random (but valid) data, and then overwrite only the bits we care about for the use-case we’re trying to test.
The column and relational metadata described above is enough to build a model we can use to generate arbitrarily complex object graphs. What we need is a build step that queries the info schema to fetch the metadata we’re interested in, applies a few transformations, and outputs
- clojure.spec
- specmonstah
Spec Generator
Here’s how such a tool might work. Somewhere in the codebase there’s a main method that queries the information-schema, feeds the data to the generator, and writes the specs to STDOUT. Here it is wrapped in a lein alias because we’re old skool.
$ lein from-info-schema gen-specs > src/ce_data_aggregator_tool/streams/specs/celm.clj…and in the resulting file, there are spec definitions like these
(clojure.spec.alpha/def :celm.columns.addresses/addressable-id :ce-data-aggregator-tool.streams.info-schema/banded-id)
(clojure.spec.alpha/def :celm.columns.addresses/addressable-type #{"person" "company_loan_data"})
(clojure.spec.alpha/def :celm.columns.addresses/city (clojure.spec.alpha/nilable (info-specs/string-up-to 255)))
(clojure.spec.alpha/def :celm.columns.addresses/company (clojure.spec.alpha/nilable (info-specs/string-up-to 255)))
(clojure.spec.alpha/def :celm.columns.addresses/country-id :ce-data-aggregator-tool.streams.info-schema/int)
(clojure.spec.alpha/def :celm.columns.addresses/created-at :ce-data-aggregator-tool.streams.info-schema/datetime)
(clojure.spec.alpha/def :celm.columns.addresses/debezium-manual-update
(clojure.spec.alpha/nilable :ce-data-aggregator-tool.streams.info-schema/datetime))As you can see there are a variety of datatypes (e.g. strings, dates, integers), some some domain specific specs like “banded-id”, enumerations, and when the information schema has instructed us to, we mark fields as optional.
There are also keyset definitions definitions like these
(clojure.spec.alpha/def :celm.tables/addresses
(clojure.spec.alpha/keys
:req-un
[:celm.columns.addresses/addressable-id
:celm.columns.addresses/addressable-type
:celm.columns.addresses/city
:celm.columns.addresses/company
:celm.columns.addresses/country-id
:celm.columns.addresses/created-at
:celm.columns.addresses/debezium-manual-update
:celm.columns.addresses/id
:celm.columns.addresses/name
:celm.columns.addresses/phone-number
:celm.columns.addresses/postal-code
:celm.columns.addresses/province
:celm.columns.addresses/resident-since
:celm.columns.addresses/street1
:celm.columns.addresses/street2
:celm.columns.addresses/street3
:celm.columns.addresses/street-number
:celm.columns.addresses/updated-at]))This is a bit more straightforward. Just an enumeration of all the columns in each table.
We check the generated files into the repo and have a test-helper that loads them before running any tests. This means you can also have the specs at your fingertips from the REPL and easily inspect any generated objects using your editor. Whenever the schema is updated, we can re-generate the specs and we’ll get a nice diff reflecting the schema change.
Column Query
All the specs you see above were generated from the database itself. Most folks manage the database schema using some sort of schema migration tool so it seems a bit wasteful to also painstakingly update test data generators every time you make a schema change. I’ve worked on projects where this is done and it is not fun at all. Here’s the query to fetch the column metadata from database
(def +column-query+
"Query to extract column meta-data from the mysql info schema"
"select c.table_name
, c.column_name
, case when c.is_nullable = 'YES' then true else false end as is_nullable
, c.data_type
, c.character_maximum_length
, c.numeric_precision
, c.numeric_scale
, c.column_key
from information_schema.columns c
where c.table_schema = ? and c.table_name in (<table-list>)
order by 1, 2")The data from this query is mapped into clojure.spec as follows
Integer Types -> Clojure Specs
The integer types are all pretty straightforward. I got these max/min limits from the MySQL Documentation and just used Clojure.spec’s builtin “int-in” spec, making a named “s/def” for each corresponding integer type in mysql
(s/def ::tinyint (s/int-in -128 127))
(s/def ::smallint (s/int-in -32768 32767))
(s/def ::mediumint (s/int-in -8388608 8388607))
(s/def ::int (s/int-in 1 2147483647))Date Types -> Clojure Specs
For dates, we want to generate a java.sql.Date instance. This plays
nicely with clojure.jdbc. They can be used as a parameter in calls to
insert or insert-multi. Here we’re generating a random integer between
0 and 30 and subtracting that from the current date so that we get a
reasonably recent date.
For similar reasons, we want to generate a java.sql.Timestamp for datetimes. For these, we generate an int between 0 and 10k and substract from the currentMillisSinceEpoch to get a reasonably recent timestamp.
(s/def ::date (s/with-gen #(instance? java.sql.Date %)
#(gen/fmap (fn [x]
(Date/valueOf (time/minus (time/local-date) (time/days x))))
(s/gen (s/int-in 0 30)))))
(s/def ::datetime (s/with-gen #(instance? java.sql.Timestamp %)
#(gen/fmap (fn [x]
(Timestamp. (-> (time/minus (time/instant) (time/seconds x))
.toEpochMilli)))
(s/gen (s/int-in 0 10000)))))Decimal Types -> Clojure Specs
Decimals are bit more involved. In SQL you get to specify the precision and scale of a decimal number. The precision is the number of significant digits, and the scale is the number of digits after the decimal point.
For example, the number 99 has precision=2 and scale=0. Whereas the number 420.50 has precision=5 and scale=2.
Ultimately though, for each possible precision, there exists a range of doubles that can be expressed using a simple “s/double-in :min :max”. The mapping for decimals just figures out the max/min values and generates the corresponding spec.
(defn precision-numeric [max min]
(s/with-gen number?
#(s/gen (s/double-in :max max :min min))))
(cond
;; ...
(= data_type "decimal")
(let [int-part (- numeric_precision numeric_scale)
fraction-part numeric_scale
max (read-string (format "%s.%s"
(string/join "" (repeat int-part "9"))
(string/join "" (repeat fraction-part "9"))))
min (read-string (format "-%s.%s"
(string/join "" (repeat int-part "9"))
(string/join "" (repeat fraction-part "9"))))]
`(precision-numeric ~max ~min))
;;....
)String Types -> Clojure Specs
Strings are pretty simple. We define the “string-up-to” helper to define a generator that will generate random strings with variable lengths up-to a maximum of the specified size. The max size comes from the “character_maximum_length” field of the columns table in the information-schema.
For longtext, rather than allowing 2 to the power of 32 really long strings, we use a max of 500. Otherwise the generated values would be unreasonably large for regular use.
(defn string-up-to [max-len]
(s/with-gen string?
#(gen/fmap (fn [x] (apply str x))
(gen/bind (s/gen (s/int-in 0 max-len))
(fn [size]
(gen/vector (gen/char-alpha) size))))))
(cond
...
(contains? #{"char" "varchar"} data_type)
`(info-specs/string-up-to ~character_maximum_length)
...)Custom Types -> Clojure Specs
Custom types are our “get-out” clause for the cases where we need a generator that doesn’t fit in with the rules above. For example strings that are really enumerations, integers that have additional constraints not captured in the database schema. The “banded-id” referenced above is an example of this.
That’s it! With these mappings, we can generate specs for each database column of interest, and keysets for each table of interest. Assuming a database exists with “likes”, “tweets”, and “users” tables, after generating and loading the specs, we could generate a “like” value and inspect it at the REPL.
Some databases I’ve worked on don’t define relational constraints at the database level so if you’re working on one of these databases, you could take the generated data and just insert it straight in there without worrying about creating the corresponding related records.
But if your database does enforce relational integrity, you need to create a graph of objects (the users, the tweet, and the like), and ensure that the users are inserted first, then the tweet, and finally the like. For this, you need Specmonstah.
Specmonstah
Specmonstah builds on spec by allowing us to define relationships and constraints between entity key sets. This means that if you have a test that requires the insertion of records for a bunch of related entities, you can use monstah-spec to generate the object graph and do all the database IO in the correct order.
Foreign Key Query
Here’s the query to extract all that juicy relationship data from the information-schema.
(def +foreign-key-query+
"Query to extract foreign key meta-data from the mysql info schema"
"select kcu.table_name
, kcu.column_name
, kcu.referenced_table_name
, referenced_column_name
from information_schema.key_column_usage kcu
where kcu.referenced_table_name is not null
and kcu.table_schema = ? and kcu.table_name in (<table-list>)
order by 1, 2")
And here’s how we need to represent that data so that specmonstah will generate object graphs for us. There are fewer concepts to take care of here.
:addresses
{:prefix :addresses,
:spec :celm.tables/addresses,
:relations {:country-id [:countries :id]},
:constraints {:country-id #{:uniq}}},The :prefix names the entity in the context of the graph of objects
generated by specmonstah. The :spec is the clojure.spec generator
used to generate values for this entity. This refers to one of the
clojure.spec entity keysets generated from the column metadata. In
the :relations field each key represents a field which is a link to
another table. The key is the field name. The value is a pair where
the first item is the foreign table, and the second item is the
primary key of that table. The :constraints field determines how
values are constrained within the graph of generated data.
Specmonstah provides utilities for traversing the graph of objects so
that you can enumerate them in dependency order. We can use these
utilities to define gen-for-query which takes a specmonstah schema,
and a graph query (which seems kinda like a graphql query), and
returns the raw data for the test object graph, in order, ready to be
inserted into a database.
(defn gen-for-query
([schema query xform]
(let [types-by-ent (fn [ents-by-type]
(->> (reduce into []
(for [[t ents] ents-by-type]
(for [e ents]
[e t])))
(into {})))]
(let [db (sg/ent-db-spec-gen {:schema schema} query)
order (or (seq (reverse (sm/topsort-ents db)))
(sm/sort-by-required db (sm/ents db)))
attr-map (sm/attr-map db :spec-gen)
ents-by-type (sm/ents-by-type db)
ent->type (types-by-ent ents-by-type)]
(->> order
(map (fn [k]
[(ent->type k) (k attr-map)]))
(map xform)))))
([schema query]
(gen-for-query schema query (fn [[ent v]]
[:insert ent v]))))In the intro, I promised I would show how the information schema was leveraged to test a “change data capture” pipeline at Funding Circle. The function above is a key enabler of this. The rest of this post attempts to explain the background to the following tweet.
Mergers and Acquisition
Here’s a diagram representing a problem we’re trying to solve. We have three identically structured databases (one for each country in which we operate in Europe). And an integrator whose job it was to merge each table from the source databases into a unified stream, and apply a few transformations before passing it along to the view builders which join up related tables for entry into salesforce.
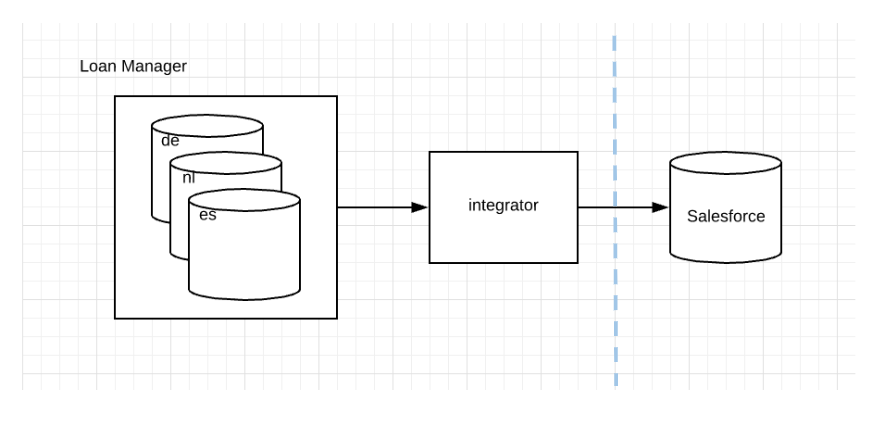
The integrator was implemented using debezium to stream the database changes into kafka, and kafka streams to apply the transformations.
We called the bit before the view builders “the wrangler” and the test from the previous slide performed a “full-stack” test of one of the wranglers (i.e. load the data into mysql and check that it comes out the other side as expected in kafka after being copied into kafka by debezium and transformed by our own kafka streams application).
The Test Machine
In order to explain how this test-helper works, we need to introduce one final bit of tech. The test-machine, invented by the bbqd-goats team at Funding Circle. I talked about the test-machine at one of the London Clojure meetups last year in more detail but will try to give you the elevator pitch here.
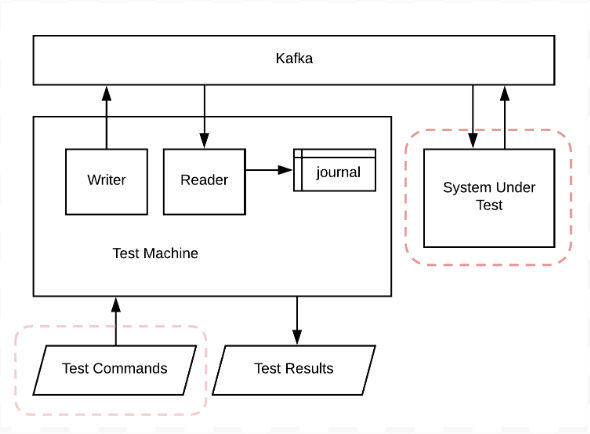
The core value proposition of the test-machine is that it is a great way to test any system whose input or output can be captured by kafka. You tell it which topics to watch, submit some test-commands, and the test-machine will sit there loading anything that gets written by the system under test to the watched topics into the journal. The journal is a clojure agent which means you can add watchers that get invoked whenever the journal is changed (e.g. when data is loaded into it from a kafka topic). The final test-command is usually a watcher which watches the journal until the supplied predicate succeeds.
Also included under the jackdaw.test namespace are some fixture
building functions for carrying out tasks that are frequently required
to setup the system under test. Things like creating kafka topics,
creating connectors, starting kafka streams. The functions in this
namespace are higher-order fixture functions so they usually accept
parameters to configure what exactly they will do, and return a
function compatible for use with clojure.test’s use-fixtures
(i.e. the function returned accepts a parameter t which is invoked
at some appropriate point during the fixture’s execution).
There is also a with-fixtures macro which is just a bit of syntactic
sugar around join-fixtures so that each test can be explicit
about which fixtures it requires rather than rely on a global list
of fixtures specified in use-fixtures.
Building the Test Helper
The test-wrangler function is just the helper function that brings all this together.
- The data generator
- The test setup
- Inserting the data to the database using the test-machine
- Defining a watcher that waits until the corresponding data appears in the journal after being slurped in from kafka.
But it all stems from being able to use the generated specs to generate the input test-data. Everything else uses the generated data as an input
For example, from the input data, we can generate a :do! command that
inserts the records into the database in the correct order. Before that,
we’ve already used the input data to figure out which topics need to be
created by the topic-fixture and which tables need to be truncated in the
source database. And finally, we use the input data to figure
out how to parameterize the debezium connector with which tables to monitor.
(defn test-wrangler
"Test a wrangler by inserting generated data into mysql, and then providing both the generated
data and the wrangled data (after allowing it to pass through the debezium connector) to an
assertion function
The test function should expect a map with the following keys...
:before The generated value that was inserted into the DB
:after The corresponding 'wrangled' value that eventually shows up in the topic
:logs Any logs produced by the system under test
"
{:style/indent 1}
[{:keys [schema logs entity before-fn after-fn build-fn watch-fn out-topic-override] :as wrangle-opts} test-fn]
(println (str (new java.util.Date)) "Testing" entity)
(let [inputs (info/gen-for-entity schema entity 1)
before (before-fn inputs)
topic-metadata {:before (dbz-topic "test_input" "fc_de_prod" (info/underscore (name entity)))
entity (wrangled-topic entity 1 (select-keys wrangle-opts [:out-topic-override]))
:de (dbz-topic "loan_manager" "fc_de_prod" (info/underscore (name entity)))
:es (dbz-topic "loan_manager" "fc_es_prod" (info/underscore (name entity)))
:nl (dbz-topic "loan_manager" "fc_nl_prod" (info/underscore (name entity)))}
logger (sc/make-test-logger logs)
{:keys [results journal]} (fix/with-fixtures [(fix/topic-fixture +kafka-config+ topic-metadata)
(fn [t]
(jdbc/with-db-connection [db +mysql-spec+]
(jdbc/with-db-transaction [tx db]
(without-constraints tx
(fn []
(doseq [e (map second inputs)]
(jdbc/execute! tx (format "truncate %s;" (info/underscore (name e)))))
(t))))))
(connector-fixture {:base-url +dbz-base-url+
:connector (dbz-connector "fc_de_prod" inputs)})
(fix/kstream-fixture {:topology (partial build-fn logger)
:config (sut/config)})]
(jd.test/with-test-machine (jd.test/kafka-transport +kafka-config+ topic-metadata)
(fn [machine]
(jd.test/run-test machine
[[:println "> Starting test ..."]
[:do! (fn [_]
(jdbc/with-db-connection [db +mysql-spec+]
(jdbc/with-db-transaction [tx db]
(process-mysql-commands tx inputs))))]
[:println "> Watching for results ..."]
[:watch (every-pred
(partial watch-fn inputs "fc_es_prod")
(partial watch-fn inputs "fc_de_prod")
(partial watch-fn inputs "fc_nl_prod"))
{:timeout 45000}]
[:println "> Got results, checking ..."]]))))]
(if (every? #(= :ok (:status %)) results)
(test-fn {:results results
:before before
:after (after-fn inputs journal)
:journal journal
:logs @logs})
(throw (ex-info "One or more test steps failed: " {:results results})))
(println (str (new java.util.Date)) "Testing complete (check output for failures)")))Assertion Helpers
After applying the test-commands, the test-helper uses callbacks
provided by the author to extract from the journal the data of
interest. In this case, we basically want before/after representations
of the data. If you check above, that is what is going on where we’re
calling test-fn with the extracted data.
Since the test-fn is provided by the user they can define it however they like but we found it useful to define it as a composition of a number of tests that were largely independent but share this common contract of wanting to see the before/after representations of the data.
The do-assertions function is again just a bit of syntactic sugar
that allows the test-author to just enumerate a bunch of domain specific
test declarations that roll up into a single test function that matches
the signature expected by the call to test-fn above.
(defn do-assertions
[& assertion-fns]
(fn [args]
(doseq [afn assertion-fns]
(afn args))))
(defn includes?
[included-keys]
(fn [{:keys [after]}]
(println " - checking includes?" included-keys)
(is (every? #(clojure.set/superset? (set (keys %)) after)))))
(defn excludes?
[excluded-keys]
(fn [{:keys [before after]}]
(println " - checking excludes?" excluded-keys)
(doseq [k excluded-keys]
(testing (format "checking %s is excluded" k)
(is (every? #(not (contains? % k)) after))))))
(defn uuids?
[uuid-keys]
(fn [{:keys [before after]}]
(println " - checking uuids?" uuid-keys)
(doseq [k uuid-keys]
(testing (format "checking %s is a uuid" k)
(is (every? #(uuid? (java.util.UUID/fromString (get % k))) after))))))